C# / .NET Core, download a forum thread
Once I needed to download a multi-page forum thread (more than 1000 pages) into a single-page document. So I wrote a .NET Core utility, which is presented in this article.
Of course, it is not a universal forum thread downloader, but actually it can be one, because the only thing you need to do in order to adapt it to a different forum - change regular expressions for parsing.
Okay, here’s the thread (printable version, for simplicity):
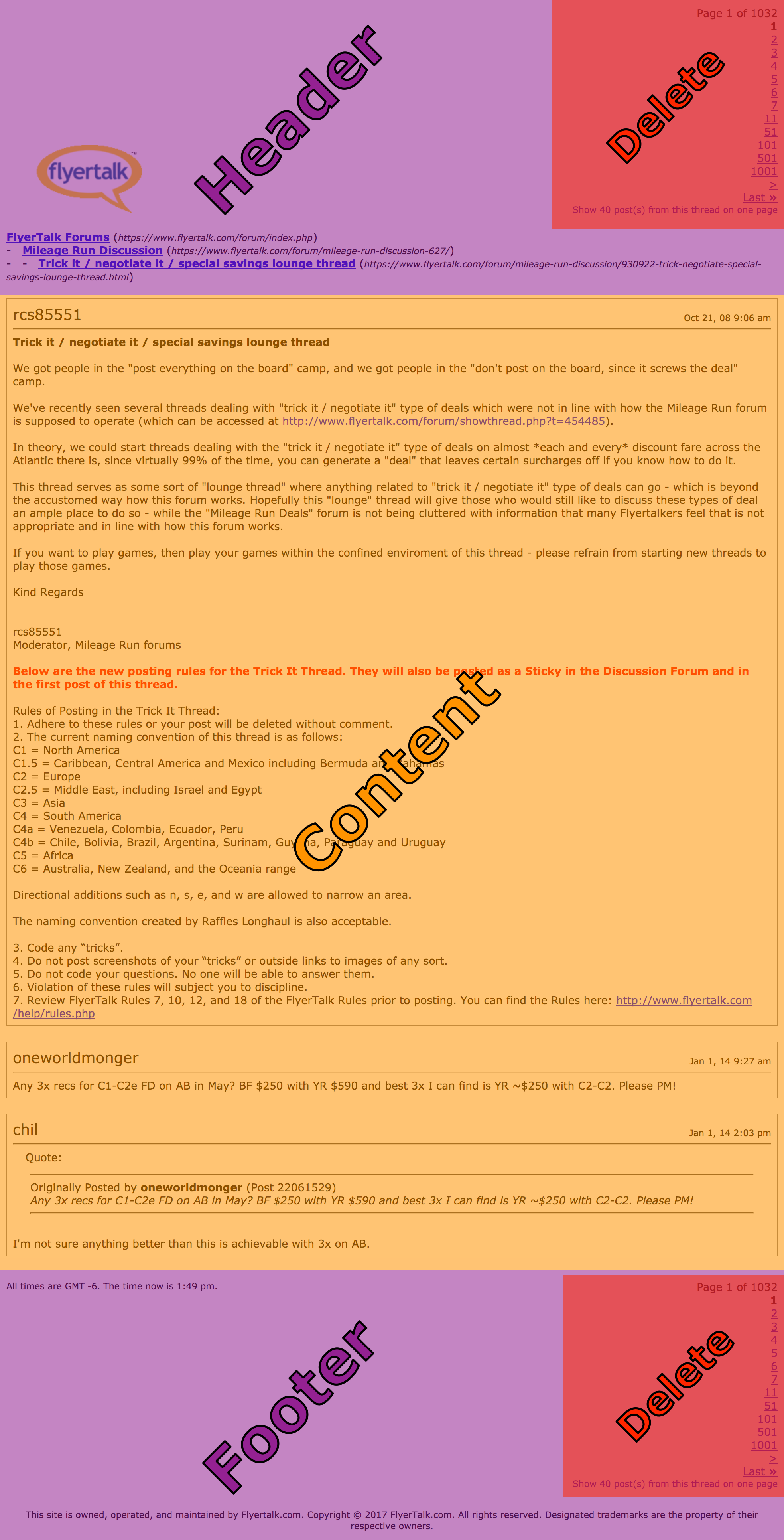
The plan is:
- Get
header, delete navigation links from it and inject custom styles; - Recursevily download
contentfrom all pages; - Get
footerand delete navigation links from it; - Save everything to file.
Algorithm flowchart looks like the following:

Sure, it’s not the most beautiful and efficient algorithm possible. For example, you can already see that actually it’s a bad idea to have the footer processing that might fail in the very end of program - it should be right after header processing.
But anyway, it’s a pretty easy one to implement. The only difficult part here is to compose correct regular expressions. If you don’t know yet, there is an outstanding online tool for that: https://regex101.com
And here’s the implementation:
using System;
using System.IO;
using System.Net.Http;
using System.Text;
using System.Text.RegularExpressions;
using System.Threading.Tasks;
using System.Xml.Linq;
// TODO: Don't accumulate the whole file in memory, implement some buffer and append file on disk chunk by chunk
// TODO: Remote server can ban your IP for so many requests, implement some IP-address switching mechanism
// TODO: Looking for footer should be happening right after processing header (store it in some variable and append after getting content is finished)
// TODO: Find better and more reliable regular expressions
// TODO: Add exceptions, especially for downloading part
namespace forum_thread_downloader
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine($"[{DateTime.Now.ToString()}] Downloading has started\n- - -");
// create an instance of the class and initialize settings (first page link and regexes)
TopicDownloader td = new TopicDownloader(
"https://www.flyertalk.com/forum/mileage-run-discussion/930922-trick-negotiate-special-savings-lounge-thread-printerfriendly.html",
@"<a rel=""next"" .*(https:\/\/.*.html).*<\/a>",
@"<!DOCTYPE html>.*<\/div>.{0,4}<br \/>",
@"<table.*<\/table>.{0,4}<br \/>.{0,4}<div>",
@"(<table class=""tborder"".*).{0,2}<br \/>.{0,4}<br \/>.{0,4}<table cellpadding=""0"".*",
@"<br \/>.{0,4}<table cellpadding=""0"".*<\/html>",
@"<br \/>.{0,4}<table.*<\/table>"
);
StringBuilder topicPageBuilder = new StringBuilder();
if (td.DownloadTopic(topicPageBuilder))
{
// save everything to file
File.WriteAllText($"topic.html", topicPageBuilder.ToString());
}
Console.WriteLine($"- - -\n[{DateTime.Now.ToString()}] Downloading has finished");
}
class TopicDownloader
{
public TopicDownloader(
string link,
string reNP,
string reH, string reHL,
string reC,
string reF, string reFL
)
{
_threadLink = link;
_reNextPage = reNP;
_reHeader = reH;
_rePlaceHeader = new Regex(reHL, RegexOptions.Singleline);
_reContent = reC;
_reFooter = reF;
_rePlaceFooter = new Regex(reFL, RegexOptions.Singleline);
_pageNumber = 0;
}
/// <summary>
/// Link to the first page of the topic
/// </summary>
private string _threadLink;
/// <summary>
/// Regex for next page link
/// </summary>
private readonly string _reNextPage;
/// <summary>
/// Regex for header
/// </summary>
private readonly string _reHeader;
/// <summary>
/// Regex for deleting navigation links from header
/// </summary>
private readonly Regex _rePlaceHeader;
/// <summary>
/// Regex for page content
/// </summary>
private readonly string _reContent;
/// <summary>
/// Regex for footer
/// </summary>
private readonly string _reFooter;
/// <summary>
/// Regex for deleting navigation links from footer
/// </summary>
private readonly Regex _rePlaceFooter;
/// <summary>
/// Current page number
/// </summary>
private int _pageNumber;
public bool DownloadTopic(StringBuilder topicPageBuilder)
{
// try to download the page
var rez = Task.Run(async () =>
{
var response = await DownloadPage(_threadLink);
return response;
});
// error
if (rez.Result.Item1 != 200)
{
Console.WriteLine($"Some error. Status code: {rez.Result.Item1}");
return false;
}
string webpage = rez.Result.Item2;
// find header
if (_pageNumber == 0)
{
var matchHeader = Regex.Match(
webpage,
_reHeader,
RegexOptions.Singleline
);
if (matchHeader.Success)
{
// delete base and add style
Regex rePlace = new Regex("<base.*-->");
string headerWObase = rePlace.Replace(
matchHeader.Groups[0].Value,
"<link rel=\"stylesheet\" href=\"threadStyle.css\" />"
);
// delete navigation links and save
topicPageBuilder.Append(
_rePlaceHeader.Replace(headerWObase, "<div>")
);
}
else
{
Console.WriteLine("[error] Couldn't find header");
return false;
}
}
topicPageBuilder.Append($@"<div align=""center""><h1>Page {_pageNumber + 1}</h1></div>");
// find content
var matchContent = Regex.Match(
webpage,
_reContent,
RegexOptions.Singleline
);
if (matchContent.Success)
{
topicPageBuilder.Append(matchContent.Groups[1].Value);
}
else
{
Console.WriteLine("[error] Couldn't find content");
return false;
}
Console.WriteLine($"Page {_pageNumber + 1} has been processed");
_threadLink = GetNextPage(webpage);
// debug
//if (_pageNumber > 3) { _threadLink = string.Empty; }
if (!string.IsNullOrEmpty(_threadLink))
{
//Console.WriteLine(_threadLink);
_pageNumber++;
return DownloadTopic(topicPageBuilder);
}
else
{
// find footer
var matchFooter = Regex.Match(
webpage,
_reFooter,
RegexOptions.Singleline
);
if (matchFooter.Success)
{
// delete navigation links and save
topicPageBuilder.Append(
_rePlaceFooter.Replace(matchFooter.Groups[0].Value, "")
);
}
else
{
Console.WriteLine("[error] Couldn't find footer");
return false;
}
Console.WriteLine("End of topic");
return true;
}
}
/// <summary>
/// Parses the string looking for a link to the next page
/// </summary>
/// <param name="a">string to parse</param>
/// <returns>link to the next page</returns>
private string GetNextPage(string a)
{
var match = Regex.Match(a, _reNextPage);
if (match.Success)
{
return match.Groups[1].Value;
}
else
{
return string.Empty;
}
}
/// <summary>
/// Download page with given URL
/// </summary>
/// <param name="URL">link to the page</param>
/// <returns>HTTP status code and page as string</returns>
public static async Task<Tuple<int, string>> DownloadPage(string URL)
{
using (var httpClient = new HttpClient())
{
var httpResponse = await httpClient.GetAsync(URL);
var httpContent = await httpResponse.Content.ReadAsStringAsync();
return new Tuple<int, string>(
(int)httpResponse.StatusCode,
httpContent
);
}
}
}
}
}Here’s the threadStyle.css I injected:
body {
width: 70%;
margin: auto;
}
table.tborder {
margin-top: 15px;
border: 2px solid;
}
tbody > tr > td {
color: darkgreen;
font-weight: bold;
}
h1 {
margin-top: 50px;
margin-bottom: 50px;
}And that’s the result (full page is around 14 MB and several kilometres long, so here’s just a fragment):

Complete project source code can be found here.



