Querying astronomy databases in ADQL via TAP
There are several astronomy databases that store various information about space objects such as stars and planets. Some (most?) of those databases expose their data via TAP interface, so it can be queried using ADQL.
Here I’ll be telling about how to get data from such sources and what sort of issues/problems one can encounter.
How to query data
Sending requests
Very simplified description for how this works is that you send SQL-like queries as a part of query string to a TAP-endpoint URL of a database/datasource via HTTP POST request (or HTTP GET, if you are fine with cached results).
An example of one such request being sent with cURL:
$ curl -X "POST" "http://voparis-tap-planeto.obspm.fr/tap/sync?REQUEST=doQuery&LANG=ADQL&FORMAT=JSON&QUERY=SELECT%20granule_uid,%20mass,%20radius%20FROM%20exoplanet.epn_core%20WHERE%20star_name%20%3D%20%27Kepler-107%27%20ORDER%20BY%20granule_uid"Here’s the same request in a more readable form:
POST http://voparis-tap-planeto.obspm.fr/tap/sync
?REQUEST=doQuery
&LANG=ADQL
&FORMAT=JSON
&QUERY=SELECT granule_uid, mass, radius FROM exoplanet.epn_core WHERE star_name = 'Kepler-107' ORDER BY granule_uidAs you can see, the QUERY parameter is indeed a pretty much regular SQL query (but here’s some more information about ADQL specifics):
SELECT granule_uid, mass, radius
FROM exoplanet.epn_core
WHERE star_name = 'Kepler-107'
ORDER BY granule_uidAnd as the FORMAT parameter is set to JSON, the response to this request will look like this:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Date: Sun, 20 Feb 2022 17:31:52 GMT
Content-Type: application/json
Server: TwistedWeb/18.9.0
{
"data":
[
[
"Kepler-107 b",
0.01104,
0.137
],
[
"Kepler-107 c",
0.02954,
0.142
],
[
"Kepler-107 d",
0.01196,
0.077
],
[
"Kepler-107 e",
0.02706,
0.259
]
],
"contains": "table",
"params":
{
"contains": "params"
},
"columns":
[
{
"dbtype": "text",
"xtype": null,
"utype": null,
"description": "Internal table row index Unique ID in data service, also in v2. Can be alphanumeric.",
"name": "granule_uid",
"datatype": "char",
"ucd": "meta.id",
"arraysize": "*",
"ref": null,
"id": "granule_uid",
"unit": ""
},
{
"dbtype": "double precision",
"xtype": null,
"utype": null,
"description": "Mass of the planet",
"name": "mass",
"datatype": "double",
"ucd": "phys.mass",
"arraysize": null,
"ref": null,
"id": "mass",
"unit": "'jupiterMass'"
},
{
"dbtype": "double precision",
"xtype": null,
"utype": null,
"description": "Radius of the planet",
"name": "radius",
"datatype": "double",
"ucd": "phys.size.radius",
"arraysize": null,
"ref": null,
"id": "radius",
"unit": "'jupiterRad'"
}
]
}But be aware that not all the services support JSON output. Other possible formats are CSV, XML and VOTable - a semi-binary format (meta-information in XML and Base64-encoded data), which is actually the only format that is required to be supported by every TAP service (all other formats are optional).
Sure enough, I needed an programmatic way to work with these queries, and as I wasn’t too eager to implement sending requests and processing results myself, I started looking for a library that would do that for me, and preferably that would be a Python library, as I’m doing my data analysis in Jupyter notebooks.
PyVO
Almost immediately I discovered The Extrasolar Planets Encyclopaedia API tutorial, which is referring to PyVO library.
It is rather easy to use. First, install it:
$ pip install pyvoand then you can use it in your Python code:
import pyvo
import pandas
from tabulate import tabulate
service = pyvo.dal.TAPService("http://voparis-tap-planeto.obspm.fr/tap")
tableName = "exoplanet.epn_core"
fields = [
"star_name",
"star_teff",
"granule_uid",
"mass",
#"mass_error_min",
#"mass_error_max",
"radius"
#"radius_error_min",
#"radius_error_max",
#"semi_major_axis"
]
starName = "Kepler-106"
queryPlanets = " ".join((
f"SELECT {', '.join(fields)}",
f"FROM {tableName}",
f"WHERE star_name = '{starName}'",
"ORDER BY granule_uid"
))
# check the final query string
#print("Query to execute: ", queryPlanets)
# execute the query
results = service.search(queryPlanets)
print("Total planets found:", len(results))
# fields datatypes can be extracted too
#print(resultPlanets.fielddescs)The PyVO results can be then printed using tabulate:
# print results as a table
print(
tabulate(
resultPlanets.to_table(),
headers=resultPlanets.fieldnames,
tablefmt="psql"
)
)
# +-------------+-------------+---------------+---------+----------+
# | star_name | star_teff | granule_uid | mass | radius |
# |-------------+-------------+---------------+---------+----------|
# | Kepler-106 | 5858 | Kepler-106 b | 0.01668 | 0.073 |
# | Kepler-106 | 5858 | Kepler-106 c | 0.033 | 0.223 |
# | Kepler-106 | 5858 | Kepler-106 d | 0.02549 | 0.085 |
# | Kepler-106 | 5858 | Kepler-106 e | 0.035 | 0.228 |
# +-------------+-------------+---------------+---------+----------+or, better yet, it can be turned into a Pandas object:
resultPandas = results.to_table().to_pandas("granule_uid")which can be displayed in a nicer manner, if you are using a Jupyter notebook client that supports display():
with pandas.option_context('display.max_rows', None, 'display.max_columns', None):
display(resultPandas)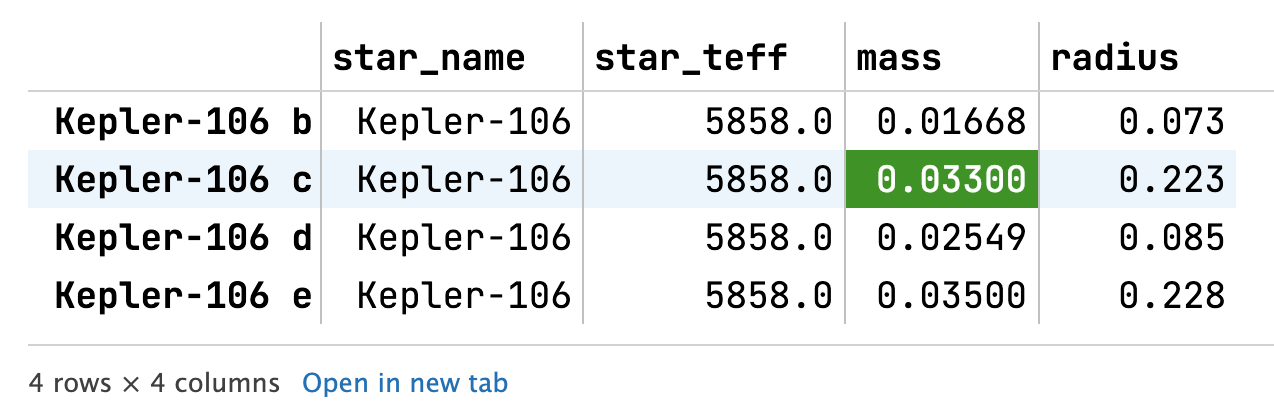
This screenshot is taken from DataSpell, but VS Code supports display() too (even though it might be underlined there as unknown).
Finally, results can be saved to a file:
# as a NumPy object
#import numpy
#numpy.save("./results.npy", resultPlanets.to_table())
#tbl = numpy.load("./results.npy")
# or as a pickle (it's a pickle! pickle fiiiiiile!)
resultPandas.to_pickle("./results.pkl")
#tbl = pandas.read_pickle("./results.pkl")If you haven’t used Pandas before, you absolutely definitely should, as it makes working with table data very convenient.
A sandbox application
Soon enough I discovered that I need a faster way to query data, for when I’d like to quickly check some values.
Opening a Jupyter notebook in Java-based DataSpell or in Electron-based VS Code is too damn slow. All the waiting for the environment to load and for Jupyter server to start, modifying queries in cells and scrolling between results and code, urgh.
Running bare Python scripts from terminal is faster, but then viewing the results isn’t that nice, especially if there are a lot of columns in the resulting table, so it gets wrapped in the terminal window. And again, constantly switching between code editor and terminal window isn’t very convenient.
Having been annoyed enough by the inconveniences of both options, I decided to write a small GUI application for the sole purpose of executing ADQL queries and browsing results in a scrollable table. There surely must be at least several already existing applications for that, but I’ve managed to find only TOPCAT, which in my opinion is quite ugly, clumsy (no offense, that’s just the way Java-based applications usually are) and too overloaded with functionality (but that’s more of a compliment, really). So yeah, I decided to make one of my own.
At first I wanted to create a native Mac OS application using SwiftUI, which I’ve been wanting to try out for a long time. But even though Mac OS is my main environment, I often work on Windows too, and sometimes on GNU/Linux too, so a cross-platform framework would be a better choice.
The next candidate was Qt, but then I remembered that I read about Python binding for Dear ImGui - Dear PyGui - which was a perfect variant, because most of the work would be then taken care of by PyVO, and I’d only need to handle the GUI part. It’s true that I could’ve taken PySide or PyQt and still benefit from relying on PyVO, but I reckoned that ImGui-based application will be more lightweight and responsive, plus I wanted to try something new.
And so here’s what I’ve come up with:
If video doesn’t play in your browser, you can download it here.
Very nice indeed! Cross-platform application (powered by GLFW), with almost native performance (but not quite, as I notice Python ears here and there) and not too horrible GUI. Some might even say, beautifully ascetic.
While we are here, I can say that Dear PyGui turned out to be even better than I expected. It is quite an easy and comfortable tooling for creating GUI application. It took me just 3 days to get from the very scratch to the working application that was executing queries and displaying results in a table widget. And most of that time I was working on styling and theme customization, rather than on the actual functionality.
You can install the current application version from PyPI:
$ pip install tap-adql-sandbox
$ tap-adql-sandbox --helpAnd here’s the project source code.
TAP services with astronomical data
There are several astronomical databases that expose their data via TAP interface. So far I’ve been working with these ones:
- NASA Exoplanet Archive:
https://exoplanetarchive.ipac.caltech.edu/TAP - Paris Astronomical Data Centre:
http://voparis-tap-planeto.obspm.fr/tap - Gaia:
https://gea.esac.esa.int/tap-server/tap(also some ADQL examples) - SIMBAD:
http://simbad.cds.unistra.fr/simbad/sim-tap/sync
All of the TAP-services (should) support a certain set of standard functions. For instance, you can query the service availability:
$ curl http://voparis-tap-planeto.obspm.fr/tap/availability
<avl:availability xmlns:avl="http://www.ivoa.net/xml/VOSIAvailability/v1.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.ivoa.net/xml/VOSIAvailability/v1.0 http://vo.ari.uni-heidelberg.de/docs/schemata/VOSIAvailability-v1.0.xsd">
<avl:available>true</avl:available>
<avl:upSince>2022-02-05T12:44:11Z</avl:upSince>
</avl:availability>And get a list of available tables:
$ curl http://voparis-tap-planeto.obspm.fr/tap/tableswhich can also be queried with ADQL:
SELECT table_name, description
FROM tap_schema.tables
ORDER BY table_nameas well as columns from a particular table:
SELECT column_name, datatype, description
FROM tap_schema.columns
WHERE table_name = 'exoplanet.epn_core'
ORDER BY column_nameAbout access and (not) abusing the service
I haven’t yet encountered a service that would limit access to its data, and I believe that this is the way things should be - that kind of data must remain open for the scientific community.
In turn, you too need to be a responsible user - do not execute crazy queries that fetch a milliard of columns with bazillion of rows. If your query doesn’t have narrow enough WHERE clause, do add a TOP limiter to your SELECT, for example:
SELECT TOP 11
star_name, granule_uid, mass, radius
FROM exoplanet.epn_coreProblems and challenges
Working with the data, I did stumble upon various differences and peculiarities among TAP services.
NASA Exoplanet Archive
Almost all the problems I had were with NASA Exoplanet Archive database. At the same time, the data from NASA seems to be the most updated and trustworthy, so I have mixed feelings about this source.
PS vs PSCompPars
There are two main tables in the database that you are likely to use: PS and PSCompPars. The difference between them is described in the Choosing the Right Table For Your Needs section. In short, the PS table is organized in a way that there is a row for every publication and the set of parameters described in that publication, so there can be several rows per planet (and star?); while PSCompPars has exactly one row per planet, and every parameter should have a value from the latest publication, and the publication is provided in the PARAMETER-NAME_reflink field/column.
So it’s obvious that one should use PSCompPars, right? Well, for me it was not so obvious, and I actually went with PS (details below).
No simple mass values
Unlike ps table, pscomppars doesn’t have “simple” mass (and probably other) values, for instance pl_massj and pl_msinij. Instead, the mass-related parameters are stored like this:
SELECT column_name, datatype, description
FROM tap_schema.columns
WHERE table_name='pscomppars' AND column_name LIKE 'pl_bmass%'
ORDER BY column_nameResults found: 13
+-------------------+------------+------------------------------------------------------+
| column_name | datatype | description |
|-------------------+------------+------------------------------------------------------|
| pl_bmasse | double | Planet Mass or Mass*sin(i) [Earth Mass] |
| pl_bmasse_reflink | char | Planet Mass or Mass*sin(i) [Earth Mass] Reference |
| pl_bmasseerr1 | double | Planet Mass or Mass*sin(i) [Earth Mass] Upper Unc. |
| pl_bmasseerr2 | double | Planet Mass or Mass*sin(i) [Earth Mass] Lower Unc. |
| pl_bmasselim | int | Planet Mass or Mass*sin(i) [Earth Mass] Limit Flag |
| pl_bmassestr | char | Planet Mass or Mass*sin(i) [Earth Mass] |
| pl_bmassj | double | Planet Mass or Mass*sin(i) [Jupiter Mass] |
| pl_bmassj_reflink | char | Planet Mass or Mass*sin(i) [Jupiter Mass] Reference |
| pl_bmassjerr1 | double | Planet Mass or Mass*sin(i) [Jupiter Mass] Upper Unc. |
| pl_bmassjerr2 | double | Planet Mass or Mass*sin(i) [Jupiter Mass] Lower Unc. |
| pl_bmassjlim | int | Planet Mass or Mass*sin(i) [Jupiter Mass] Limit Flag |
| pl_bmassjstr | char | Planet Mass or Mass*sin(i) [Jupiter Mass] |
| pl_bmassprov | char | Planet Mass or Mass*sin(i) Provenance |
+-------------------+------------+------------------------------------------------------+So instead of pl_massj one should use pl_bmassj, right, but then what does one suppose to use instead of pl_msinij? Turns out, it’s the same pl_bmassj! And the type of what is stored in pl_bmassj is provided in pl_bmassprov (does it also correspond for pl_bmasse?). Here all the possible values of pl_bmassprov:
SELECT COUNT(*) AS "How many", pl_bmassprov
FROM pscomppars
GROUP BY pl_bmassprov+------------+------------------+
| how many | pl_bmassprov |
|------------+------------------|
| 872 | Msini |
| 1335 | Mass |
| 21 | Msin(i)/sin(i) |
| 2786 | M-R relationship |
+------------+------------------+So okay, apparently you’d need to add some more complexity to your queries and additionally check whether the value in pl_bmassj is of type Mass (for pl_massj in ps) or Msini (for pl_msinij in ps)? And what are the Msin(i)/sin(i) and M-R relationship types? By the way, there is another issue related to that.
Finally, as you can see, the pl_bmassprov field/column is not a dictionary value but a mere string! Needless to say how that adds to unreliability of querying the data.
Calculated values
If we query pl_radj for HD 95872 b planet from ps table, then we’ll see that out of all publications there is no known value for it:
SELECT hostname, pl_name, pl_radj, pl_pubdate
FROM ps
WHERE pl_name = 'HD 95872 b'
ORDER BY pl_pubdate DESCResults found: 2
+------------+------------+-----------+--------------+
| hostname | pl_name | pl_radj | pl_pubdate |
|------------+------------+-----------+--------------|
| HD 95872 | HD 95872 b | nan | 2017-03 |
| HD 95872 | HD 95872 b | nan | 2016-02 |
+------------+------------+-----------+--------------+However, if we query the same from the pscomppars table, then suddenly there is a value:
SELECT hostname, pl_name, pl_radj, pl_radj_reflink
FROM pscomppars
WHERE pl_name = 'HD 95872 b'Results found: 1
+------------+------------+-----------+----------------------------------------------------------------------------------------------+
| hostname | pl_name | pl_radj | pl_radj_reflink |
|------------+------------+-----------+----------------------------------------------------------------------------------------------|
| HD 95872 | HD 95872 b | 1.16 | <a refstr=CALCULATED_VALUE href=/docs/composite_calc.html target=_blank>Calculated Value</a> |
+------------+------------+-----------+----------------------------------------------------------------------------------------------+which, according to reflink, is a “calculated value”, so it is questionable whether one can rely on it or not. And if you’d like to exclude “calculated values” from your results, then apparently you’d need to add a (reliable enough) condition for *_reflink fields, which are strings, of course. Oh joy.
Missing values
If we query pl_msinij for HD 10180 d planet from ps table, then we’ll get values from two publications:
SELECT hostname, pl_name, pl_massj, pl_msinij, pl_pubdate
FROM ps
WHERE pl_name = 'HD 10180 d'
ORDER BY pl_pubdate DESCResults found: 2
+------------+------------+------------+-------------+--------------+
| hostname | pl_name | pl_massj | pl_msinij | pl_pubdate |
|------------+------------+------------+-------------+--------------|
| HD 10180 | HD 10180 d | nan | 0.0378 | 2014-09 |
| HD 10180 | HD 10180 d | nan | 0.03697 | 2011-04 |
+------------+------------+------------+-------------+--------------+So the latest value is 0.0378 from 2014-09 publication. But if we query this from pscomppars, then we’ll only get 0.03697 value, which is from 2011-04 publication, so it is not the latest one available:
SELECT hostname, pl_name, pl_bmassprov, pl_bmassj, pl_bmassj_reflink
FROM pscomppars
WHERE pl_name = 'HD 10180 d'Results found: 1
+------------+------------+----------------+-------------+--------------------------------------------------------------------------------------------------------------------------------------+
| hostname | pl_name | pl_bmassprov | pl_bmassj | pl_bmassj_reflink |
|------------+------------+----------------+-------------+--------------------------------------------------------------------------------------------------------------------------------------|
| HD 10180 | HD 10180 d | Msin(i)/sin(i) | 0.03697 | <a refstr=LOVIS_ET_AL__2011 href=https://ui.adsabs.harvard.edu/abs/2011A%26A...528A.112L/abstract target=ref> Lovis et al. 2011 </a> |
+------------+------------+----------------+-------------+--------------------------------------------------------------------------------------------------------------------------------------+On top of that, the pl_bmassprov says that pl_bmassj is of Msin(i)/sin(i) type, and so if we were looking for the Msini type, then we’d miss it. And by the way, if according to pscomppars that is Msin(i)/sin(i) type, then how can one know that this value in ps table is of that type and not of pl_msinij/Msini? Or are Msini and Msin(i)/sin(i) actually the same type? Why then it’s two different types in pscomppars table? Argh…
Okay, now back to general issues with the NASA database.
Planetary data is organized by publications
Say you’d like to get mass and radius of the Kepler-107 b planet. With PADC service the query will be this:
SELECT star_name, granule_uid, mass, radius
FROM exoplanet.epn_core
WHERE granule_uid = 'Kepler-107 b'Results found: 1
+-------------+---------------+---------+----------+
| star_name | granule_uid | mass | radius |
|-------------+---------------+---------+----------|
| Kepler-107 | Kepler-107 b | 0.01104 | 0.137 |
+-------------+---------------+---------+----------+If you’ll try to execute a similar query with NASA service, then all of a sudden you’ll get more than one result:
SELECT hostname, pl_name, pl_massj, pl_radj
FROM ps
WHERE pl_name = 'Kepler-107 b'Results found: 13
+------------+--------------+------------+-----------+
| hostname | pl_name | pl_massj | pl_radj |
|------------+--------------+------------+-----------|
| Kepler-107 | Kepler-107 b | nan | nan |
| Kepler-107 | Kepler-107 b | nan | nan |
| Kepler-107 | Kepler-107 b | nan | nan |
| Kepler-107 | Kepler-107 b | nan | nan |
| Kepler-107 | Kepler-107 b | nan | 0.138 |
| Kepler-107 | Kepler-107 b | nan | 0.142 |
| Kepler-107 | Kepler-107 b | nan | 0.139 |
| Kepler-107 | Kepler-107 b | nan | nan |
| Kepler-107 | Kepler-107 b | nan | 0.141 |
| Kepler-107 | Kepler-107 b | nan | nan |
| Kepler-107 | Kepler-107 b | 0.01104 | 0.137 |
| Kepler-107 | Kepler-107 b | nan | nan |
| Kepler-107 | Kepler-107 b | nan | nan |
+------------+--------------+------------+-----------+What the hell, right? 13 results instead of just one. Turns out, the data is stored by publications, which can be determined by the pl_pubdate column. Let’s add it to the query:
SELECT hostname, pl_name, pl_massj, pl_radj, pl_pubdate
FROM ps
WHERE pl_name = 'Kepler-107 b'
ORDER BY pl_pubdate DESCResults found: 13
+------------+--------------+------------+-----------+------------------+
| hostname | pl_name | pl_massj | pl_radj | pl_pubdate |
|------------+--------------+------------+-----------+------------------|
| Kepler-107 | Kepler-107 b | nan | nan | 2019-03 |
| Kepler-107 | Kepler-107 b | 0.01104 | 0.137 | 2019-02 |
| Kepler-107 | Kepler-107 b | nan | 0.142 | 2018-10 |
| Kepler-107 | Kepler-107 b | nan | nan | 2018-08-16 |
| Kepler-107 | Kepler-107 b | nan | nan | 2017-08-31 00:00 |
| Kepler-107 | Kepler-107 b | nan | nan | 2016-07 |
| Kepler-107 | Kepler-107 b | nan | 0.138 | 2016-05 |
| Kepler-107 | Kepler-107 b | nan | nan | 2015-09-24 |
| Kepler-107 | Kepler-107 b | nan | 0.141 | 2015-08 |
| Kepler-107 | Kepler-107 b | nan | nan | 2014-12-18 |
| Kepler-107 | Kepler-107 b | nan | nan | 2014-12-04 |
| Kepler-107 | Kepler-107 b | nan | 0.139 | 2014-03 |
| Kepler-107 | Kepler-107 b | nan | nan | 2014-01-08 |
+------------+--------------+------------+-----------+------------------+That is something you need to know about NASA’s database, otherwise you might fetch obsolete/inaccurate data for your research.
Furthermore, if you’ll need the latest pl_radj value, then you would execute the following query:
SELECT TOP 1 pl_radj
FROM ps
WHERE pl_name = 'Kepler-107 b' AND pl_radj IS NOT NULL
ORDER BY pl_pubdate DESC…you would, but the results will surprise you once again, because NASA’s TOP clause is broken!
It becomes especially complicated if you need to get the latest value of a parameter for all the planets in the system. For now, I’ve come up with the following CTE (common table expression) using ranking:
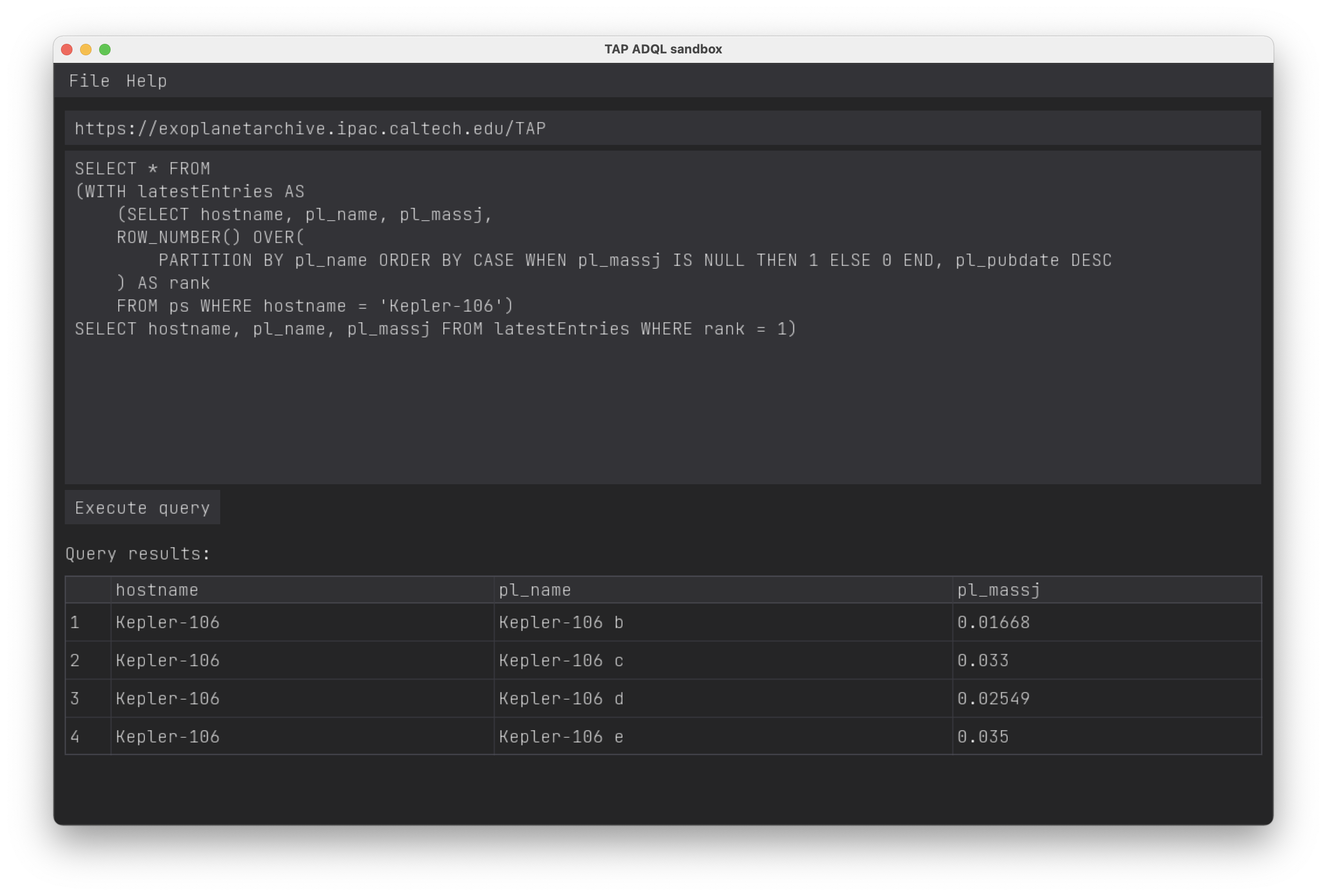
SELECT * FROM
(WITH latestEntries AS
(SELECT hostname, pl_name, pl_radj, pl_pubdate,
ROW_NUMBER() OVER(
PARTITION BY pl_name ORDER BY CASE WHEN pl_radj IS NULL THEN 1 ELSE 0 END, pl_pubdate DESC
) AS rank
FROM ps WHERE hostname = 'Kepler-107')
SELECT hostname, pl_name, pl_radj, pl_pubdate FROM latestEntries WHERE rank = 1 ORDER BY pl_name)Results found: 4
+------------+--------------+-----------+--------------+
| hostname | pl_name | pl_radj | pl_pubdate |
|------------+--------------+-----------+--------------|
| Kepler-107 | Kepler-107 b | 0.137 | 2019-02 |
| Kepler-107 | Kepler-107 c | 0.142 | 2019-02 |
| Kepler-107 | Kepler-107 d | 0.077 | 2019-02 |
| Kepler-107 | Kepler-107 e | 0.259 | 2019-02 |
+------------+--------------+-----------+--------------+Looks pretty complex, but I am not sure if there is any other way.
The documentation says that there is default_flag field/column, which you could think to use to query the latest data, but (and I wonder if database maintainers are aware of this) this obviously won’t work in case when a planet has its parameters spread across several publications. For example:
SELECT hostname, pl_name, pl_massj, pl_radj, pl_pubdate, default_flag
FROM ps
WHERE pl_name = 'HR 8799 b'
ORDER BY pl_pubdate DESCResults found: 4
+------------+-----------+------------+-----------+--------------+----------------+
| hostname | pl_name | pl_massj | pl_radj | pl_pubdate | default_flag |
|------------+-----------+------------+-----------+--------------+----------------|
| HR 8799 | HR 8799 b | nan | nan | 2016-08 | 0 |
| HR 8799 | HR 8799 b | nan | nan | 2016-03 | 0 |
| HR 8799 | HR 8799 b | nan | 0.6 | 2016-03 | 0 |
| HR 8799 | HR 8799 b | 7 | 1.2 | 2008-11 | 1 |
+------------+-----------+------------+-----------+--------------+----------------+So if you trusted blindly the default_flag and took the values from 2008-11 publication, then you’d miss the newer pl_radj value from 2016-03 publication.
Planets from the same system have different stellar data
If we take HR 8799 system as an example, then its planet HR 8799 b has st_teff value of 7204.58 from the publication on 2016-08:
SELECT * FROM
(WITH latestEntries AS
(SELECT hostname, pl_name, st_teff, pl_pubdate,
ROW_NUMBER() OVER(
PARTITION BY pl_name ORDER BY CASE WHEN st_teff IS NULL THEN 1 ELSE 0 END, pl_pubdate DESC
) AS rank
FROM ps WHERE hostname = 'HR 8799')
SELECT hostname, pl_name, st_teff, pl_pubdate FROM latestEntries WHERE rank = 1 ORDER BY pl_name)Results found: 4
+------------+-----------+-----------+--------------+
| hostname | pl_name | st_teff | pl_pubdate |
|------------+-----------+-----------+--------------|
| HR 8799 | HR 8799 b | 7204.58 | 2016-08 |
| HR 8799 | HR 8799 c | 7204.58 | 2016-08 |
| HR 8799 | HR 8799 d | 7204.58 | 2016-08 |
| HR 8799 | HR 8799 e | 7400 | 2019-03 |
+------------+-----------+-----------+--------------+As this is a stellar parameter, one would expect it to be the same for every planet in the system, but as you can see other planets in that system, such as HR 8799 e, have different values (there also might be no value at all). How to know which one is the right one? Because pl_pubdate filed name implies that it applies to planetary parameters, and there are no host_pubdate or star_pubdate fields in the table.
So we can only assume that pl_pubdate applies to stellar parameters too, and that means that if you are working with just HR 8799 b, and you are not interested in other planets, still you cannot just take 7204.58 value, you’ll need to execute an additional query to get the first not null st_teff value ordered by publication date (yes, also with CTE and ranking, because TOP is broken) from all the planets in the system.
No way to get the latest data
Following the previous issue, there actually seems to be no way to get data from the latest available publication. For instance, on this page we can see that this very same HR 8799 star has even newer publication from Swastik et al. 2021, which states st_teff value of 7339:
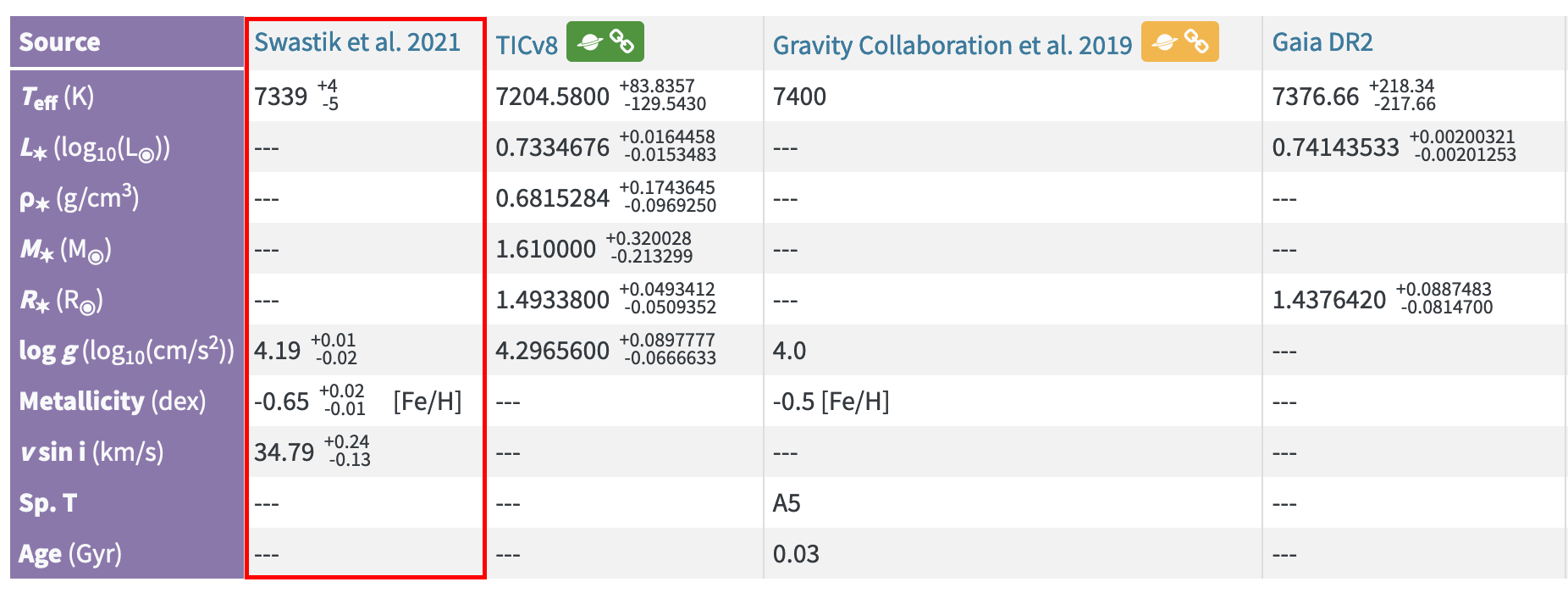
How can one get this value from via TAP interface? Or the 7376.66 value from “Gaia DR2”, for that matter? Neither of these are available in the ps table. Is there some other table with all the stellar data? And can it be joined with ps table by the hostname or some other identifier? I didn’t find answers to that.
Here’s another example. If we take Kepler-450 system, then web-interface says that the latest publication on Kepler-450 b is Yoffe et al. 2021, and there pl_radj, pl_radjerr2, pl_radjerr1 have values of 0.54272 (-0.00020/+0.00020):
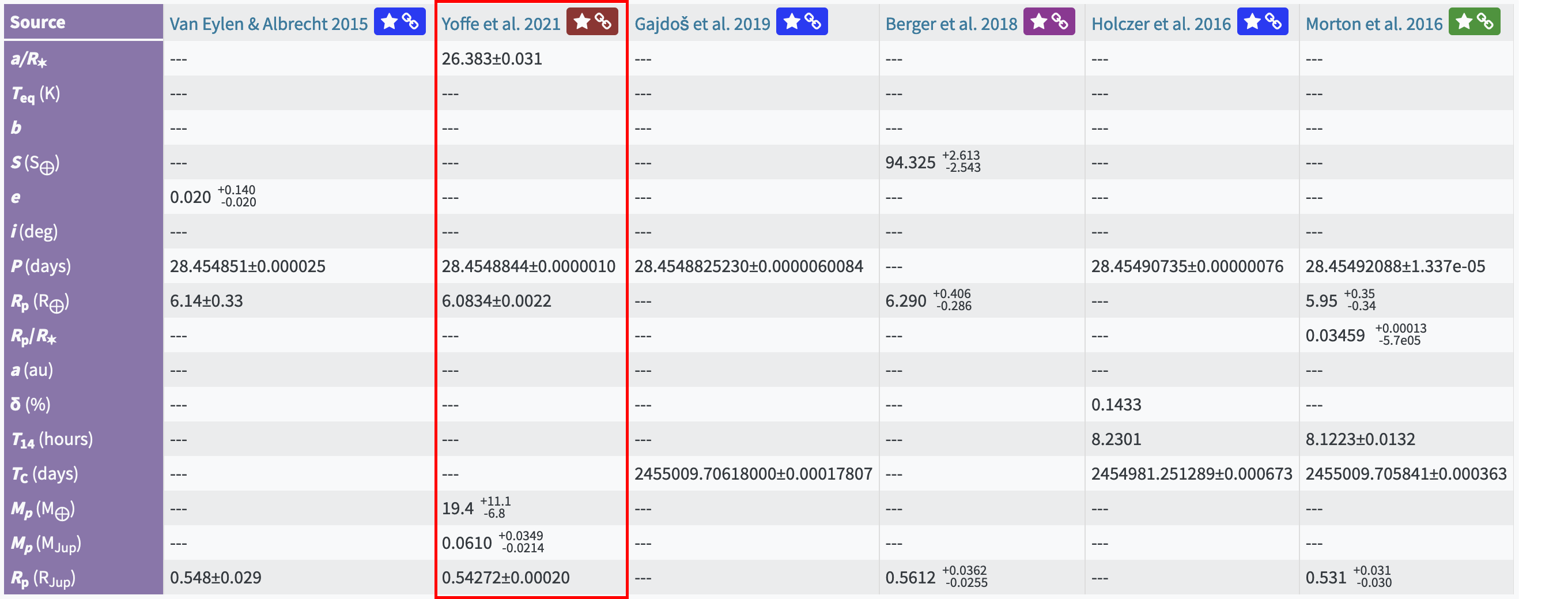
But if we’ll query those via TAP, then here’s what we’ll get:
SELECT hostname, pl_name, pl_radj, pl_radjerr2, pl_radjerr1, pl_pubdate
FROM ps
WHERE pl_name = 'Kepler-450 b' AND pl_radj IS NOT NULL
ORDER BY pl_pubdate DESCResults found: 4
+------------+--------------+-----------+---------------+---------------+--------------+
| hostname | pl_name | pl_radj | pl_radjerr2 | pl_radjerr1 | pl_pubdate |
|------------+--------------+-----------+---------------+---------------+--------------|
| Kepler-450 | Kepler-450 b | 0.543 | -0 | 0 | 2020-11 |
| Kepler-450 | Kepler-450 b | 0.561 | -0.026 | 0.036 | 2018-10 |
| Kepler-450 | Kepler-450 b | 0.531 | -0.03 | 0.031 | 2016-05 |
| Kepler-450 | Kepler-450 b | 0.548 | -0.029 | 0.029 | 2015-08 |
+------------+--------------+-----------+---------------+---------------+--------------+So, again, it does not return values from Yoffe et al. 2021, and in fact the latest that it does return is some publication from 2020-11, which is not shown via the web-interface and simply is nowhere to find! On top of that, pl_radjerr2/pl_radjerr1 have the values of 0, like there is no error at all. And it is like that for Kepler-450 c and Kepler-450 d planets too.
So not only you cannot get the latest data (which is available via web-interface), it even may return incorrect values from some unknown publications, messing up your data. A-fucking-mazing, innit.
TOP clause is broken
So yeah, here are the radius values for the Kepler-107 b planet by publication date:
SELECT pl_radj, pl_pubdate
FROM ps
WHERE pl_name = 'Kepler-107 b'
ORDER BY pl_pubdate DESCResults found: 13
+-----------+------------------+
| pl_radj | pl_pubdate |
|-----------+------------------|
| nan | 2019-03 |
| 0.137 | 2019-02 |
| 0.142 | 2018-10 |
| nan | 2018-08-16 |
| nan | 2017-08-31 00:00 |
| nan | 2016-07 |
| 0.138 | 2016-05 |
| nan | 2015-09-24 |
| 0.141 | 2015-08 |
| nan | 2014-12-18 |
| nan | 2014-12-04 |
| 0.139 | 2014-03 |
| nan | 2014-01-08 |
+-----------+------------------+As you want to get the latest value, that would be the query you’d normally execute:
SELECT TOP 1 pl_radj, pl_pubdate
FROM ps
WHERE pl_name = 'Kepler-107 b' AND pl_radj IS NOT NULL
ORDER BY pl_pubdate DESCbut here are the results that you will actually get:
Results found: 1
+-----------+--------------+
| pl_radj | pl_pubdate |
|-----------+--------------|
| 0.138 | 2016-05 |
+-----------+--------------+I know, right, why in the ass did it return 0.138 value from 2016-05 instead of 0.137 from 2019-02? Go figure!
I sent a detailed bugreport with steps to reproduce the problem to their support more than a month ago, but the issue is still not fixed. I did, however, received two e-mails from the support system with notifications that my bugreport is still being processed, so hopefully eventually this will be fixed. And who knows for how long it has been present already (from the very beginning, I imagine)? Could it even be that I’m the first one who noticed and/or bothered to report it?
As a workaround one can use the following CTE with ranking:
SELECT * FROM
(WITH latestEntries AS
(SELECT pl_radj, pl_pubdate,
ROW_NUMBER() OVER(
PARTITION BY pl_name ORDER BY CASE WHEN pl_radj IS NULL THEN 1 ELSE 0 END, pl_pubdate DESC
) AS rank
FROM ps WHERE pl_name = 'Kepler-107 b')
SELECT pl_radj, pl_pubdate FROM latestEntries WHERE rank = 1)Results found: 1
+-----------+--------------+
| pl_radj | pl_pubdate |
|-----------+--------------|
| 0.137 | 2019-02 |
+-----------+--------------+Yes, it is overcomplicated, but it works.
Missing uncertainties columns
Documentation claims that there are uncertainties values for parameters like ra, dec, glat, glon and others:
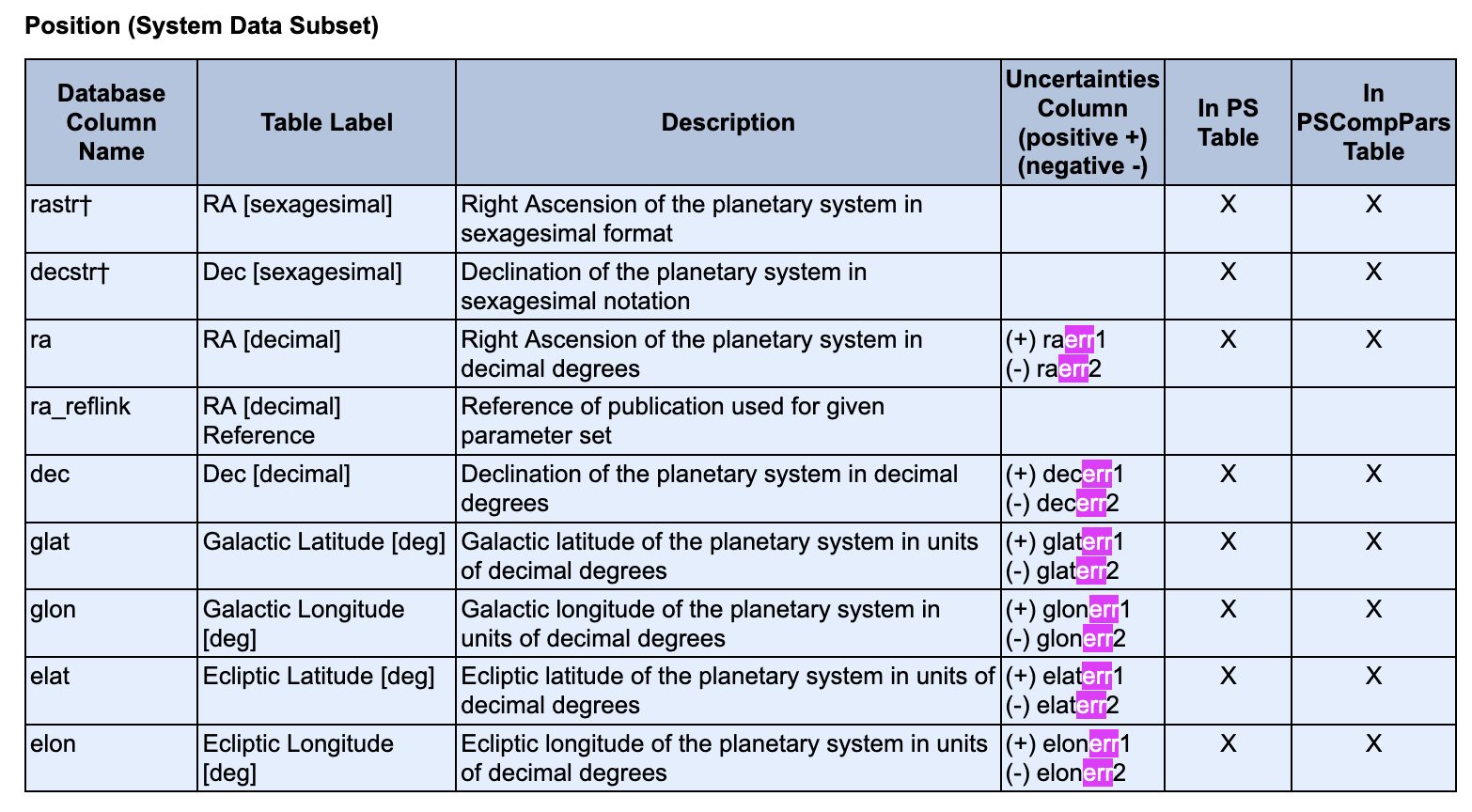
However, in reality you will get the following error trying to SELECT them:
ORA-00904: 'DECERR1': invalid identifierAnd indeed, there are no such columns in the table:
SELECT column_name, datatype, description
FROM tap_schema.columns
WHERE table_name = 'ps' AND
(
column_name LIKE 'ra%'
OR column_name LIKE 'dec%'
OR column_name LIKE 'glat%'
OR column_name LIKE 'glon%'
OR column_name LIKE 'elat%'
OR column_name LIKE 'elon%'
)
ORDER BY column_name+---------------+------------+--------------------------+
| column_name | datatype | description |
|---------------+------------+--------------------------|
| dec | double | Dec [decimal] |
| elat | double | Ecliptic Latitude [deg] |
| elon | double | Ecliptic Longitude [deg] |
| glat | double | Galactic Latitude [deg] |
| glon | double | Galactic Longitude [deg] |
| ra | double | RA [decimal] |
+---------------+------------+--------------------------+Why then they are listed in the documentation?
Inconsistent date format
In particular, within pl_pubdate column:
SELECT DISTINCT(pl_pubdate)
FROM ps
ORDER BY LENGTH(pl_pubdate) DESC
Results found: 289
+------------------+
| pl_pubdate |
|------------------|
| 2017-08-31 00:00 |
| 2014-12-04 |
| 2018-08-16 |
| 2014-01-08 |
| 2015-09-24 |
| 2014-12-18 |
| 2016-03 |
| 2016-05 |
| 2019-09 |
| 2017-07 |
| 2015-11 |
| 2024-07 |
...
Fucking hell.
Float values are rounded on SELECT but compared to originals in WHERE
This was such a shocking discovery when I noticed it more than 2 years after I started fetching data from these services. As it turns out (and this applies not only to NASA, but also to PADC and probably to other services too), float values are returned rounded on SELECT. That would be half of the problem, but NASA went an extra mile here too, and in their database these values are actually used with their full original values in WHERE clauses!
Here’s a demonstration. Let’s say we’d like to get pl_massj value for the KOI-4777.01 planet from the NASA database:
SELECT hostname, pl_name, pl_massj, pl_pubdate
FROM ps
WHERE pl_name = 'KOI-4777.01' AND pl_massj IS NOT NULL
ORDER BY pl_pubdate DESC
Results found: 1
+------------+-------------+------------+--------------+
| hostname | pl_name | pl_massj | pl_pubdate |
|------------+-------------+------------+--------------|
| KOI-4777 | KOI-4777.01 | 0.31212 | 2022-01 |
+------------+-------------+------------+--------------+
Okay, the value is 0.31212. And then some time later we’d like to get the publication reference for this value:
SELECT pl_refname
FROM ps
WHERE pl_name = 'KOI-4777.01' AND pl_massj = 0.31212
ORDER BY pl_pubdate DESC
Results found: 0
And that query returns no results! But how is it possible? I have gotten this 0.31212 value just now, why the comparison in WHERE clause did not succeed?
I’ll tell you why: this is because the actual value that is stored in this particular pl_massj field is actually much longer, and what we got on SELECT was just a rounded value, but the comparison in WHERE uses the original non-rounded value, so the query quite naturally fails to find matching results. Ну разве не пиздец?
But okay, then what is the actual value, how does one get it? I had no idea, so I just tried to cast it to REAL type on SELECT:
SELECT hostname, pl_name, pl_massj, CAST(pl_massj AS REAL) as pl_massj_real, pl_pubdate
FROM ps
WHERE pl_name = 'KOI-4777.01' AND pl_massj IS NOT NULL
ORDER BY pl_pubdate DESC
Results found: 1
+------------+-------------+------------+--------------------------+--------------+
| hostname | pl_name | pl_massj | pl_massj_real | pl_pubdate |
|------------+-------------+------------+--------------------------+--------------|
| KOI-4777 | KOI-4777.01 | 0.31212 | 0.312118104660166 | 2022-01 |
+------------+-------------+------------+--------------------------+--------------+
And here it is - 0.312118104660166! How the hell was one supposed to know that?
Just to make sure, let’s now try to get the publication reference again with this “new” value:
SELECT pl_refname
FROM ps
WHERE pl_name = 'KOI-4777.01' AND pl_massj = 0.312118104660166
ORDER BY pl_pubdate DESC
Results found: 1
+------------------------------------------------------------------------------------------------------------------------------------------------+
| pl_refname |
|------------------------------------------------------------------------------------------------------------------------------------------------|
| <a refstr=CA_NTILDE_AS_ET_AL__2022 href=https://ui.adsabs.harvard.edu/abs/2022AJ....163....3C/abstract target=ref>Cañas et al. 2022</a> |
+------------------------------------------------------------------------------------------------------------------------------------------------+
Yes, now it did find a matching record.
You might say, but this can’t be right, maybe it’s the library’s fault, so it’s PyVO who does the rounding. I certainly agree that this can’t be right, but it is not the PyVO’s fault, because here’s a bare cURL request:
$ curl -X "POST" "https://exoplanetarchive.ipac.caltech.edu/TAP/sync?REQUEST=doQuery&LANG=ADQL&FORMAT=JSON&QUERY=SELECT%20hostname,%20pl_name,%20pl_massj,%20pl_pubdate%20FROM%20ps%20WHERE%20pl_name%20=%20'KOI-4777.01'%20AND%20pl_massj%20IS%20NOT%20NULL%20ORDER%20BY%20pl_pubdate%20DESC"
and here’s what it returns:
[
{
"hostname": "KOI-4777",
"pl_name": "KOI-4777.01",
"pl_massj": 0.31212,
"pl_pubdate": "2022-01"
}
]
So it really is the NASA’s ADQL backend who returns the rounded 0.31212 instead of the actual 0.312118104660166.
To be entirely fair, NASA does somewhat warn about this, because if you check the data type for this column:
SELECT column_name, datatype, format
FROM tap_schema.columns
WHERE table_name = 'ps' AND column_name = 'pl_massj'
ORDER BY column_name
Results found: 2
+---------------+------------+----------+
| column_name | datatype | format |
|---------------+------------+----------|
| pl_massj | double | 8.5f |
| pl_massj | double | 8.5f |
+---------------+------------+----------+
then you’ll see that it is of double type and has the 8.5f format, which apparently means that it is rounded to the 5 digits after the comma/dot. So there is that, but firstly, one is supposed to somehow know that one needs to consult with this table first, and secondly, why the fuck there are two records here for the same pl_massj column in here?! If you do SELECT *, then you’ll see that all other columns in both of these pl_massj records hold the same values, so then why there are two identical records for it?
…Anyway, like I said in the beginning, the “problem” of rounded floats is present in PADC database too (although they do not have a format column in their tap_schema.columns, so there is no way to know the rounding precision):
SELECT star_name, granule_uid, mass, CAST(mass AS REAL) AS mass_real, radius, CAST(radius AS REAL) AS radius_real
FROM exoplanet.epn_core
WHERE granule_uid = 'HD 219134 b' AND mass IS NOT NULL AND radius IS NOT NULL
ORDER BY granule_uid
Results found: 1
+-------------+---------------+---------+---------------------+--------+--------------------+
| star_name | granule_uid | mass | mass_real | radius | radius_real |
|-------------+---------------+---------+---------------------+--------+--------------------|
| HD 219134 | HD 219134 b | 0.01343 | 0.01343000028282404 | 0.134 | 0.1340000033378601 |
+-------------+---------------+---------+---------------------+--------+--------------------+
…however, this is fine, because unlike NASA they do compare with the same rounded value. Look:
SELECT star_name, granule_uid
FROM exoplanet.epn_core
WHERE star_name = 'HD 219134' AND mass = 0.01343000028282404
ORDER BY granule_uid
Results found: 0
so no results when comparing with the actual non-rounded value, because:
SELECT star_name, granule_uid
FROM exoplanet.epn_core
WHERE star_name = 'HD 219134' AND mass = 0.01343
ORDER BY granule_uid
+-------------+---------------+
| star_name | granule_uid |
|-------------+---------------|
| HD 219134 | HD 219134 b |
+-------------+---------------+
it compares with the same rounded value that is returned on SELECT. As one would expect! So why isn’t it so in NASA database?
Moreover, Gaia database even returns the actual non-rounded values right away, so there is no problem there in the first place:
SELECT mass_flame, CAST(mass_flame AS REAL) as mass_flame_real, radius_flame, CAST(radius_flame AS REAL) AS radius_flame_real
FROM gaiadr3.astrophysical_parameters
WHERE source_id = 3145754895088191744
Results found: 1
+--------------------+--------------------+--------------------+--------------------+
| mass_flame | mass_flame_real | radius_flame | radius_flame_real |
|--------------------+--------------------+--------------------+--------------------|
| 0.8714732527732849 | 0.8714732527732849 | 0.9770743250846863 | 0.9770743250846863 |
+--------------------+--------------------+--------------------+--------------------+
And so what a fucking retarded piece of shit is this NASA database.
I would submit a bugreport to them, but from my experience it is pointless, because I already tried that with one other problem before, and it was never fixed (neither did I get any response).
Casting float values to VARCHAR drops the leading zero
Yet another thing where NASA’s database dropped the ball is how they cast floats to strings. The numbers not less than 1 are casted fine:
CAST(1.2345 AS VARCHAR(10))
-- result: 1.2345
but numbers that are less than 0 are casted with dropping the leading 0:
CAST(0.2345 AS VARCHAR(10))
-- result: .2345
CAST(-0.2345 AS VARCHAR(10))
-- result: -.2345
So if you are to cast the floats to VARCHAR instead of REAL to work around that problem with inconsistent values in SELECT/WHERE, then you’d be getting different values:
SELECT hostname, pl_name, pl_massj, CAST(pl_massj AS REAL) as pl_massj_real, CAST(pl_massj AS VARCHAR(30)) as pl_massj_string, pl_pubdate
FROM ps
WHERE pl_name = 'KOI-4777.01' AND pl_massj IS NOT NULL
ORDER BY pl_pubdate DESC
Results found: 1
+------------+-------------+----------+-------------------+------------------+--------------+
| hostname | pl_name | pl_massj | pl_massj_real | pl_massj_string | pl_pubdate |
|------------+-------------+----------+-------------------+------------------+--------------|
| KOI-4777 | KOI-4777.01 | 0.31212 | 0.312118104660166 | .312118104660166 | 2022-01 |
+------------+-------------+----------+-------------------+------------------+--------------+
The motherfucking piece of shit. Как говорится, я и бал.
Other databases don’t have this issue, for instance here is what you’ll get in PADC and Gaia:
CAST(1.2345 AS VARCHAR(10))
-- result: 1.2345
CAST(0.2345 AS VARCHAR(10))
-- result: 0.2345
CAST(-0.2345 AS VARCHAR(10))
-- result: -0.2345
Paris Astronomical Data Centre
The PADC database has issues too.
Obsolete data
Quite often the data is just obsolete. If you compare mass, radius and other parameters for the same planets in PADC and then in NASA, you’ll see that PADC data lags behind (with years of delay).
Let’s take Kepler-11 d planet as an example. Here are its mass and radius from PADC:
SELECT granule_uid, mass, radius
FROM exoplanet.epn_core
WHERE granule_uid = 'Kepler-11 d'+---------------+--------+----------+
| granule_uid | mass | radius |
|---------------+--------+----------|
| Kepler-11 d | 0.023 | 0.278 |
+---------------+--------+----------+and here are its mass and radius from NASA:
SELECT pl_name, pl_massj, pl_radj, pl_pubdate
FROM ps
WHERE pl_name = 'Kepler-11 d' AND (pl_massj IS NOT NULL OR pl_radj IS NOT NULL)
ORDER BY pl_pubdate DESC+-------------+------------+-----------+--------------+
| pl_name | pl_massj | pl_radj | pl_pubdate |
|-------------+------------+-----------+--------------|
| Kepler-11 d | nan | 0.3 | 2018-10 |
| Kepler-11 d | 0.0214 | 0.294 | 2017-07 |
| Kepler-11 d | nan | 0.301 | 2016-05 |
| Kepler-11 d | 0.0228 | nan | 2014-08 |
| Kepler-11 d | 0.021 | 0.265 | 2014-05 |
| Kepler-11 d | 0.023 | 0.278 | 2013-06 |
| Kepler-11 d | 0.019 | 0.306 | 2011-02 |
+-------------+------------+-----------+--------------+So what PADC has is the data from 2013-06 publication, while there were at least 5 new publications with updated data since then!
Here’s another example - planet Kepler-10 b. Data from PADC:
SELECT granule_uid, mass, radius
FROM exoplanet.epn_core
WHERE granule_uid = 'Kepler-10 b'+---------------+--------+----------+
| granule_uid | mass | radius |
|---------------+--------+----------|
| Kepler-10 b | 0.0145 | 0.132 |
+---------------+--------+----------+and data from NASA:
SELECT pl_name, pl_massj, pl_radj, pl_pubdate
FROM ps
WHERE pl_name = 'Kepler-10 b' AND (pl_massj IS NOT NULL OR pl_radj IS NOT NULL)
ORDER BY pl_pubdate DESC+-------------+------------+-----------+--------------+
| pl_name | pl_massj | pl_radj | pl_pubdate |
|-------------+------------+-----------+--------------|
| Kepler-10 b | 0.01123 | 0.133 | 2019-09 |
| Kepler-10 b | nan | 0.133 | 2018-10 |
| Kepler-10 b | 0.01019 | nan | 2017-10 |
| Kepler-10 b | nan | 0.135 | 2016-05 |
| Kepler-10 b | 0.0117 | 0.131 | 2016-03 |
| Kepler-10 b | nan | 0.131 | 2015-08 |
| Kepler-10 b | 0.0145 | 0.132 | 2015-05 |
| Kepler-10 b | 0.01 | 0.131 | 2014-07 |
| Kepler-10 b | 0.01447 | 0.13 | 2014-02 |
| Kepler-10 b | 0.014 | 0.126 | 2011-03 |
+-------------+------------+-----------+--------------+Again, PADC’s data is from 2015-05, and since then there were at least 6 new publications with updated data!
There are many planets whose data is like that in PADC. To make things worse, there is no way to determine in automated manner how old the data in PADC is, because it doesn’t have a field similar to NASA’s pl_pubdate. There are updated and modification_date fields, which look promising, but here’s what they return for the Kepler-10 b planet:
SELECT granule_uid, mass, radius, updated, modification_date
FROM exoplanet.epn_core
WHERE granule_uid = 'Kepler-10 b'+---------------+--------+----------+-----------+---------------------+
| granule_uid | mass | radius | updated | modification_date |
|---------------+--------+----------+-----------+---------------------|
| Kepler-10 b | 0.0145 | 0.132 | | 2021-02-05T07:00:00 |
+---------------+--------+----------+-----------+---------------------+So updated is just empty, and modification_date states a date that is later than the latest pl_pubdate from NASA, but still PADC stores values that have been obsolete for several years, so you cannot rely on this field either.
Untrustworthy data
With K2-266 b planet as an example, there is mass value of 0.0355:
SELECT granule_uid, mass
FROM exoplanet.epn_core
WHERE granule_uid = 'K2-266 b'+---------------+--------+
| granule_uid | mass |
|---------------+--------|
| K2-266 b | 0.0355 |
+---------------+--------+but there is no referred article, so it is unknown where this value originates from.
If we query the same data from NASA, then it returns null/nan, which is correct, as there is no publication stating this mass:
SELECT pl_name, pl_massj
FROM ps
WHERE pl_name = 'K2-266 b'+-----------+------------+
| pl_name | pl_massj |
|-----------+------------|
| K2-266 b | nan |
+-----------+------------+So where did PADC got the 0.0355 value from?
Or here’s another example, with Kepler-167 e planet. This one does have a source article, but in there it’s only a theory that this planet mass might be in a range from 0.3 to 50 mass of Jupiter, and yet PADC states that the mass is 4.0 (why on earth exactly 4.0?) with the error of -3.7/+46.0:
SELECT granule_uid, mass, mass_error_min, mass_error_max
FROM exoplanet.epn_core
WHERE granule_uid = 'Kepler-167 e'+---------------+--------+------------------+------------------+
| granule_uid | mass | mass_error_min | mass_error_max |
|---------------+--------+------------------+------------------|
| Kepler-167 e | 4 | 3.7 | 46 |
+---------------+--------+------------------+------------------+Here’s what NASA has for this planet:
SELECT pl_name, pl_massj, pl_massjerr2, pl_massjerr1, pl_pubdate
FROM ps
WHERE pl_name = 'Kepler-167 e'
ORDER BY pl_pubdate DESC+--------------+------------+----------------+----------------+------------------+
| pl_name | pl_massj | pl_massjerr2 | pl_massjerr1 | pl_pubdate |
|--------------+------------+----------------+----------------+------------------|
| Kepler-167 e | nan | nan | nan | 2019-03 |
| Kepler-167 e | nan | nan | nan | 2018-10 |
| Kepler-167 e | nan | nan | nan | 2018-08-16 |
| Kepler-167 e | nan | nan | nan | 2017-08-31 00:00 |
| Kepler-167 e | nan | nan | nan | 2016-04 |
| Kepler-167 e | nan | nan | nan | 2014-12-18 |
| Kepler-167 e | nan | nan | nan | 2014-12-04 |
| Kepler-167 e | nan | nan | nan | 2014-01-08 |
+--------------+------------+----------------+----------------+------------------+null/nan values for mass and errors, as it should be, because neither of the publications states these values.
Different names for star and planets
In NASA database there is a system Kepler-89. It’s a binary system, meaning that it has 2 stars, Kepler-89 B and KOI-94:
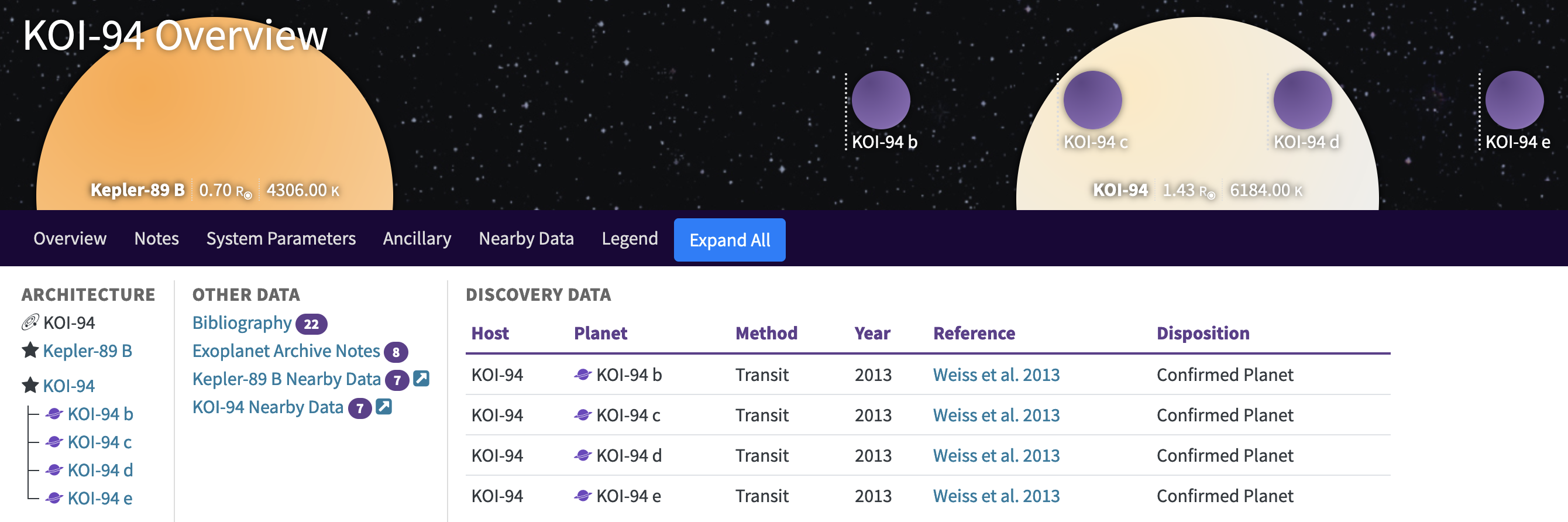
If you query planets from KOI-94 system in NASA database, then you’ll get this:
SELECT pl_name
FROM ps
WHERE hostname = 'KOI-94'
GROUP BY pl_name
ORDER BY pl_name+-----------+
| pl_name |
|-----------|
| KOI-94 b |
| KOI-94 c |
| KOI-94 d |
| KOI-94 e |
+-----------+But if you query the same from PADC:
SELECT granule_uid
FROM exoplanet.epn_core
WHERE star_name = 'KOI-94'
ORDER BY granule_uid+---------------+
| granule_uid |
|---------------|
| Kepler-89 b |
| Kepler-89 c |
| Kepler-89 d |
| Kepler-89 e |
+---------------+then all of the sudden the planets names are different. Wut.
And so if you’ll want to cross-check or enrich the data you got from one database with the data from another, you’ll need to keep in mind that that the planets might have different names there. For automated processing that means that you’ll need to keep a list of such mismatches to map names between databases (as if you didn’t have enough things to worry about already).
SIMBAD
Does not support CAST
Yeah, you cannot use CAST in SIMBAD ADQL queries:
Incorrect ADQL query: Encountered "CAST". Was expecting one of: "(" "+" "-" "*" <QUANTIFIER> "TOP" "AVG" "MAX" "MIN" "SUM" "COUNT" "BOX" "CENTROID" "CIRCLE" "POINT" "POLYGON" "REGION" "CONTAINS" "INTERSECTS" "AREA" "COORD1" "COORD2" "COORDSYS" "DISTANCE" "ABS" "CEILING" "DEGREES" "EXP" "FLOOR" "LOG" "LOG10" "MOD" "PI" "POWER" "RADIANS" "RAND" "ROUND" "SQRT" "TRUNCATE" "ACOS" "ASIN" "ATAN" "ATAN2" "COS" "COT" "SIN" "TAN" "\'" <SCIENTIFIC_NUMBER> <UNSIGNED_FLOAT> <UNSIGNED_INTEGER> "\"" <REGULAR_IDENTIFIER_CANDIDATE> <REGULAR_IDENTIFIER_CANDIDATE> "\""
(HINT: "CAST" is not supported in ADQL, but is however a reserved word. To use it as a column/table/schema name/alias, write it between double quotes.)
Some problems with strings
There are some strange problems with with queries that are using main_ID column in WHERE clause, for instance this query returns no results:
SELECT oid, main_ID
FROM basic
WHERE main_ID = 'SZ 77'
If anything, yes, those are two spaces in the identifier. Here’s also a pre-filled query on the CDS/SIMBAD website.
But if I replace = with LIKE, then the query does return a result:
SELECT oid, main_ID
FROM basic
WHERE main_ID LIKE 'SZ 77'
So for some reason a wildcard (even though there is no actual wildcard pattern here) query with LIKE does find a match, but an explicit = does not. What the fucking fuck!
It can also be reproduced with SZ 66 identifier, so explicit query returns no results:
SELECT oid, main_ID
FROM basic
WHERE main_ID = 'SZ 66'
but wildcard query does return a result:
SELECT oid, main_ID
FROM basic
WHERE main_ID LIKE 'SZ 66'
So far I’ve only noticed this issue with the IDs that start with SZ * pattern, but there might be more problematic identifiers like this. What’s common among these identifiers is that they all have two spaces, so maybe that is part of the problem somehow?
I’ve reported all that to cds-question@unistra.fr (on 2025-12-13), and while I was waiting for a response, I had to implement an crutched workaround in one of my other projects. In about a month (on 2026-01-07) they did reply and said the following:
Those identifiers were not encoded correctly in the database, because, it should have been written "Sz" and not "SZ". Anyway, it is working better now.
That does not sound exactly trustworthy or at the very least there might be something else to it, because I can almost swear that I did try the Sz (small z) identifiers too, and it did not make any difference back then. But okay, something was indeed “fixed”, because now a query with strict = operator works fine (with small z, like they said):
SELECT oid, main_ID
FROM basic
WHERE main_ID = 'Sz 66'
+---------+-----------+
| oid | main_id |
|---------+-----------|
| 2325762 | Sz 66 |
+---------+-----------+
But a query with capital Z works too:
SELECT oid, main_ID
FROM basic
WHERE main_ID = 'SZ 66'
+---------+-----------+
| oid | main_id |
|---------+-----------|
| 2325762 | Sz 66 |
+---------+-----------+
which means that string comparison is case-insensitive (is it a common thing in SQL databases?), however this case-insensitivity isn’t the same for LIKE queries, because a query with small z finds the result:
SELECT oid, main_ID
FROM basic
WHERE main_ID LIKE 'Sz 66'
but a query with capital Z does not:
SELECT oid, main_ID
FROM basic
WHERE main_ID LIKE 'SZ 66'
There are some other (new?) problems too, for instance database does not seem to care about the number of whitespace characters in the identifier - all of the following queries do return the same result, while only one should (the one with 2 whitespace characters), since it is a strict = operator:
SELECT oid, main_ID
FROM basic
-- WHERE main_ID = 'Sz 66' -- one space, should not find the result, but it does
WHERE main_ID = 'Sz 66' -- two spaces, correct
-- WHERE main_ID = 'Sz 66' -- three spaces, should not find the result, but it does
-- WHERE main_ID = 'Sz 66' -- five spaces, should not find the result, but it does
-- WHERE main_ID = 'Sz 66' -- ten spaces, should not find the result, but it does
-- ...
+---------+-----------+
| oid | main_id |
|---------+-----------|
| 2325762 | Sz 66 |
+---------+-----------+
Finally, a wildcard LIKE query with capital Z also does return a result, and the returned value is different from all the previous queries mentioned above:
SELECT oid, main_ID
FROM basic
WHERE main_ID LIKE 'SZ%66'
+---------+-------------+
| oid | main_id |
|---------+-------------|
| 2173332 | SZ II 66 |
+---------+-------------+
…although this one might not be an error, if they do in fact have this other object with a different identifier (even though it looks awefully similar).
I’ve reported all these new findings back to them (on 2026-01-09).
Overall
It is rather concerning that being a astronomer / planetary scientist you don’t have a reliable source of data about stars and planets.
Why there is more than one database about space objects, each containing intersecting/overlapping data? Why it is not one common database instead, why the efforts are spread around on several databases?
Why these databases have different numbers of stars and planets, and more importantly why do they have different data about the same stars and planets? How can a researcher know which one to use, which one has the most recent / trustworthy data? Why there is no common agreement about naming, since different databases have different names/identifiers for the same objects?
Да, с такими базулями нам не летать к далёкому космосу.
On the bright side though, having at least these databases free to use for any researcher is tremendously better than having closed/private databases or no databases at all. And hopefully the problems that I described in the article will eventually get fixed/resolved. Although I don’t find it reassuring that I have never got a response to most of the bugreports that I have submitted over the years.



